"Hmm… you're right." I fiddled with my phone. "Actually, let's watch a little video to give you a basic overview of neural nets." I pulled up a video from 3Blue1Brown's channel, which was full of great nerdy content.
The narrator, Grant, began speaking as an animation played. "This is a 3. It's sloppily written and rendered at an extremely low resolution of 28 x 28 pixels, but your brain has no trouble recognizing it as a 3. I want you to take a moment to appreciate how crazy it is that brains can do this so effortlessly. I mean, this, this and this" — he pointed to some other sloppily-written threes — "are also recognizable as threes, even though the specific values of each pixel is very different from one image to the next. The particular light-sensitive cells in your eye that are firing when you see this 3" — he held up the first 3 — "are very different from the ones firing when you see this 3" — he held up a different 3, written in different handwriting.

"But something in that crazy-smart visual cortex of yours resolves these as representing the same idea, whilst at the same time recognizing other images as their own distinct ideas. But if I told you, 'Hey, sit down and write for me a program that takes in a grid of 28 x 28 pixels like this, and outputs a single number between 0 and 10, telling you what it thinks the digit is,' well, the task goes from comically trivial to dauntingly difficult."

"As the name suggests, neural networks are inspired by the brain. But let's break that down. What are the neurons? And in what sense are they linked together? Right now, when I say 'neuron,' all I want you to think about is a thing that holds a number. Specifically, a number between 0 and 1. It's really not more than that."

"For example, the network starts with a bunch of neurons corresponding to each of the 28 x 28 pixels of the input image, which is 784 neurons in total. Each one of these holds a number which represents the grayscale value of the corresponding pixel, ranging from 0 for black pixels, up to 1 for white pixels. This number inside the neuron is called its activation. The image you might have in mind here is that each neuron is 'lit up' when its activation is a high number."
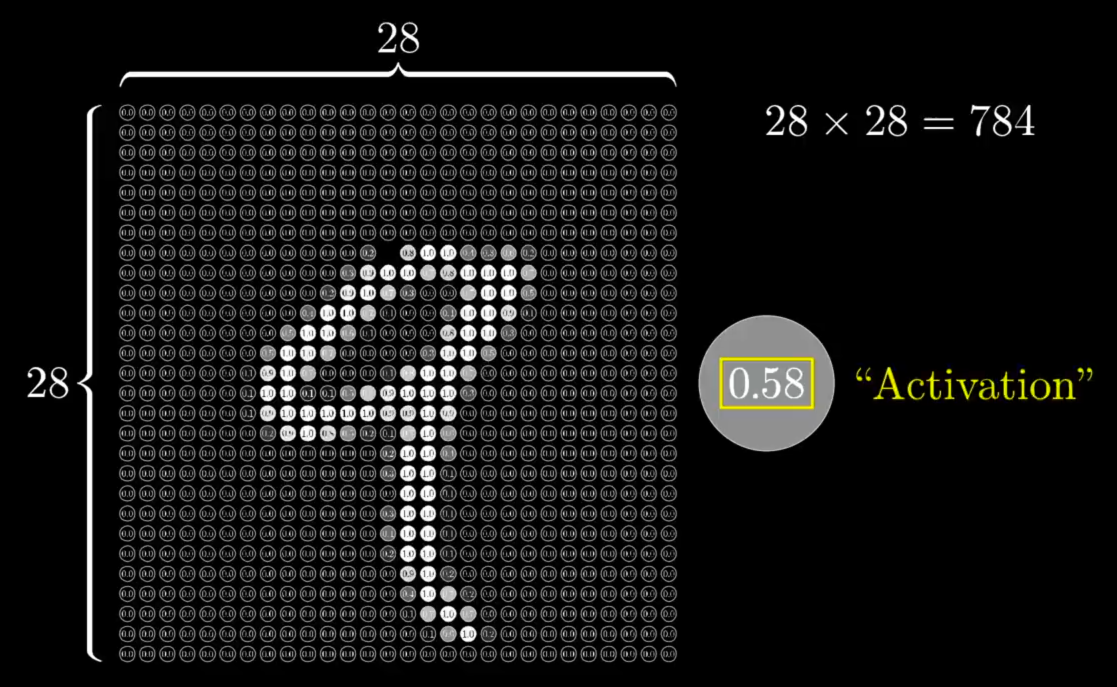
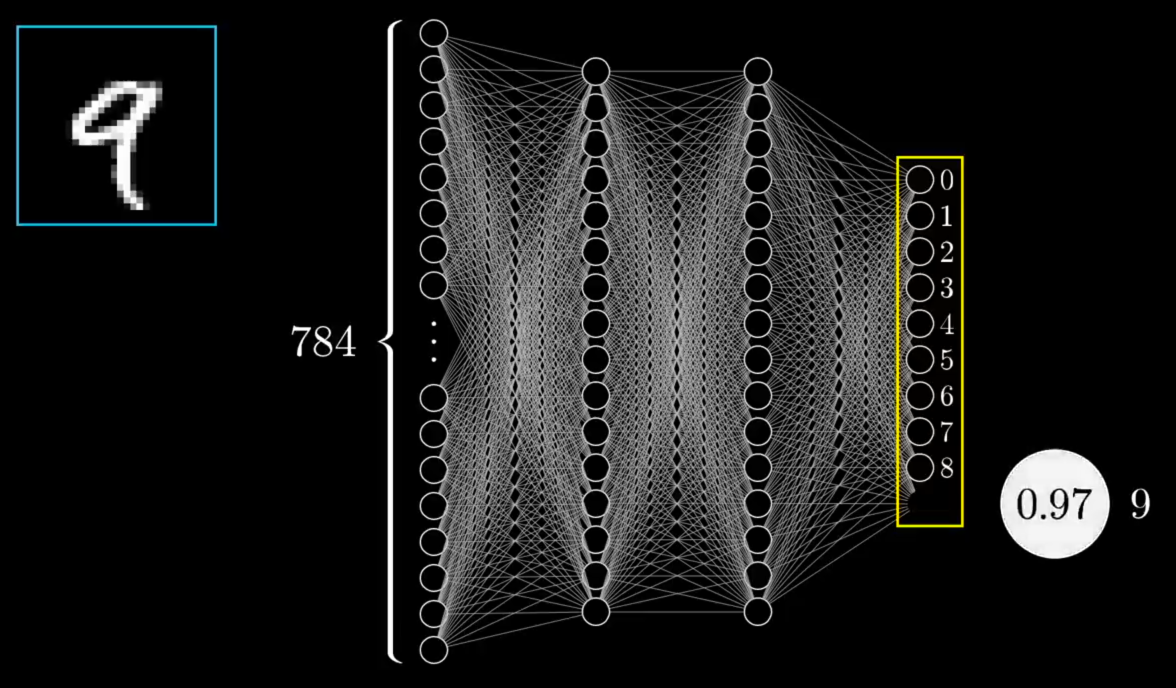
"So all of these 784 neurons make up the first layer of our network. Now, jumping over to the last layer, this has 10 neurons, each representing one of the digits. The activation between these neurons — again, some number between 0 and 1 — represents how much the system thinks that a given image corresponds with a given digit."
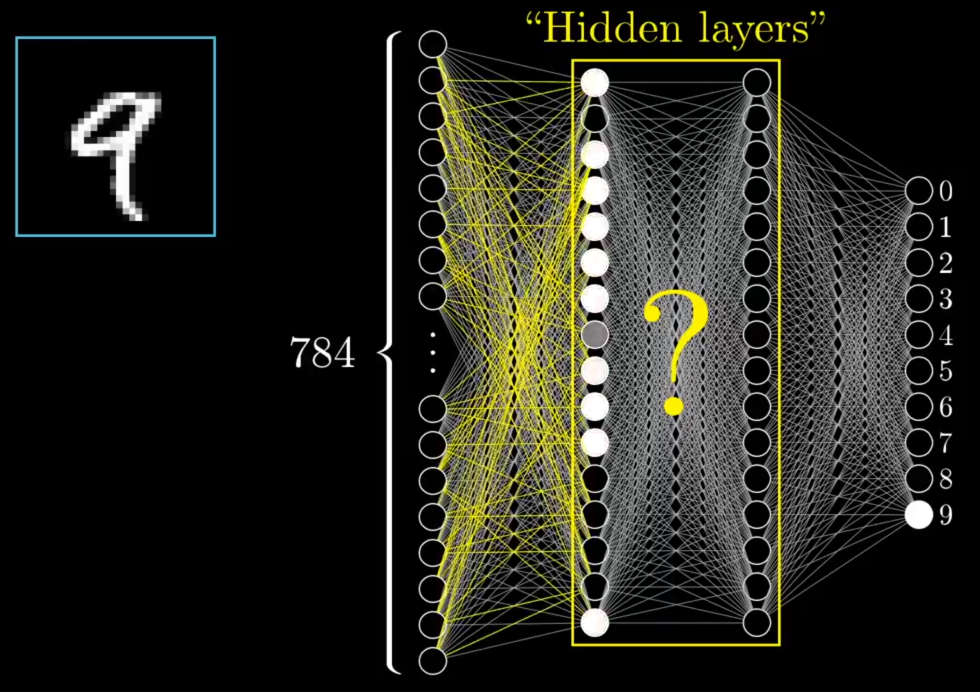
"There's also a couple of layers in between called the 'hidden layers' which, for the time being, should just be a giant question mark for how on earth this process of recognizing digits is going to be handled. In this network, I chose two hidden layers, each with 16 neurons. Admittedly, that's kind of an arbitrary choice. To be honest, I chose two layers based on how I want to motivate the structure in just a moment. And 16? Well, that was just a nice number to fit on the screen. In practice, there is a lot of room for experiment with the specific structure here.
The way the network operates, activations in one layer determine activations in the next layer." The animation showed connections between each layer lighting up in yellow as they were activated. Eventually, one single neuron in the final layer was lit up at the end, representing the final answer.
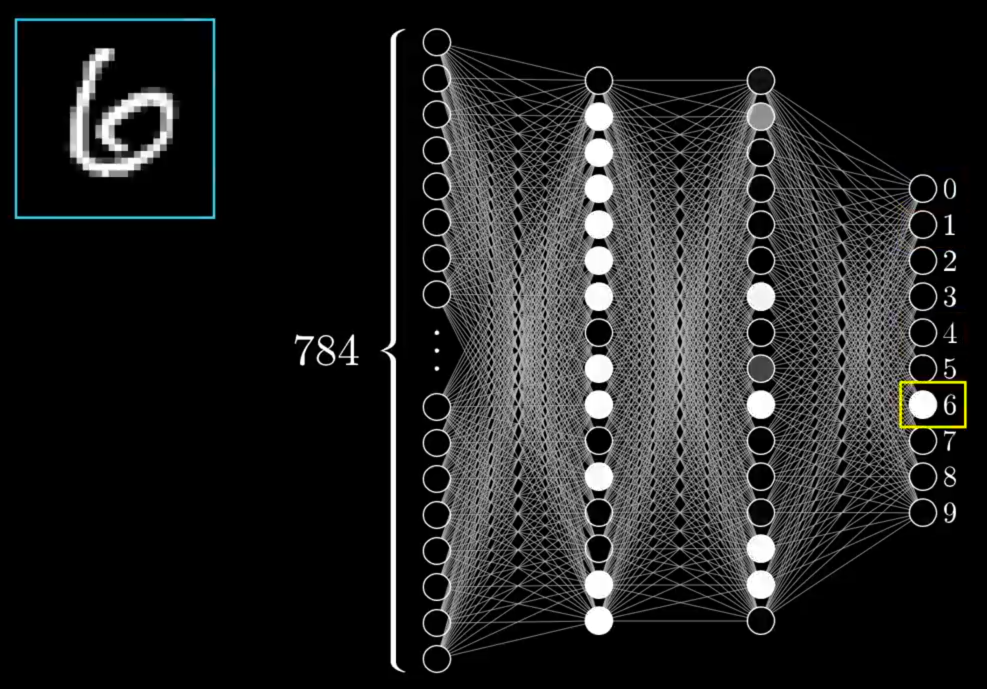
"And, of course, the heart of the network as an information processing mechanism comes down to exactly how those activations from one layer bring about activations in the next layer. It's meant to be loosely analogous to how in biological networks of neurons, some groups of neurons firing cause others to fire.
Now, the network I'm showing here has already been trained to recognize digits, and let me show you what I mean by that. It means if you feed in an image lighting up all 784 neurons in the input layer according to the brightness of each pixel in the image, that pattern of activations causes some very specific pattern in the next layer, which causes some pattern in the one after it, which finally gives some pattern in the output layer. And the brightest neuron of that output layer is the network's choice for what digit this image represents."
"And before jumping into the math for how one layer influences the next, or how training works, let's just talk about why it's even reasonable to expect a layered structure like this to behave intelligently. What are we expecting here? What is the best hope for what those middle layers might be doing?
Well, when you or I recognize digits, we piece together various components. A 9 has a loop up top and a line on the right. An 8 also has a loop up top, but it's paired with another loop down low. A 4 basically breaks down into three specific lines, and things like that."
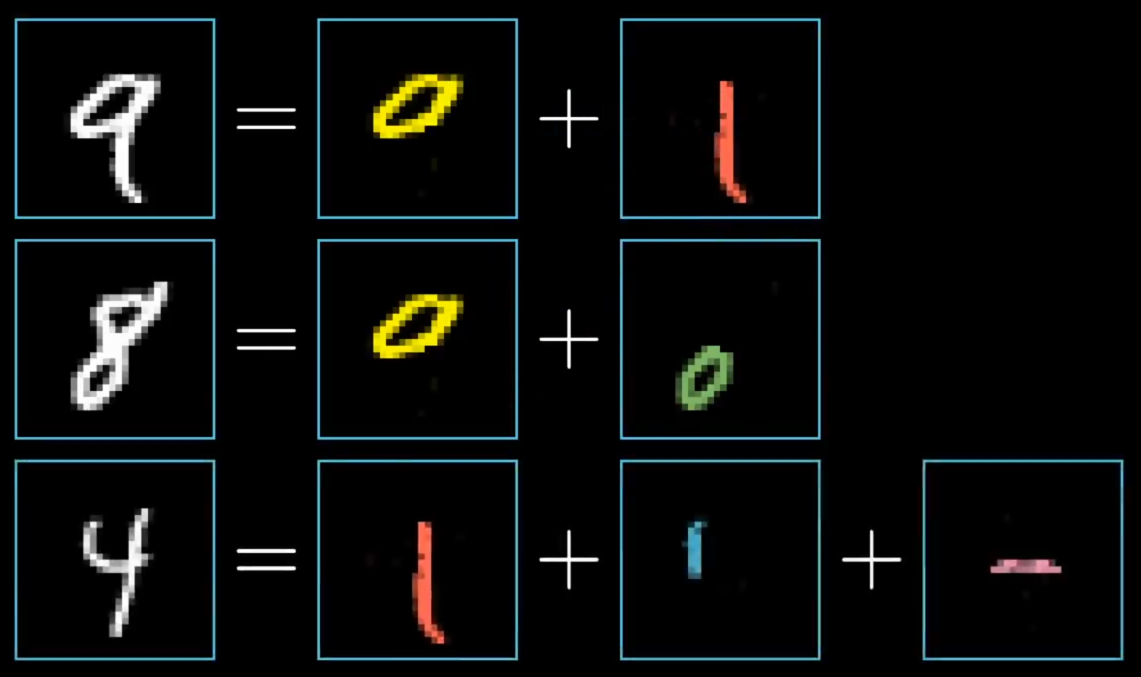
"Now, in a perfect world, we might hope that each neuron in the second-to-last layer corresponds to one of these sub-components; that anytime you feed in an image with, say, a loop up top like a 9 or an 8, there's some specific neuron whose activation is going to be close to 1. And I don't mean this specific loop of pixels." He pointed to a specific slanted loop he'd drawn. "The hope would be that any generally loopy pattern towards the top sets off this neuron. That way, going from the third layer to the last one just requires learning which combination of sub-components corresponds to which digits."
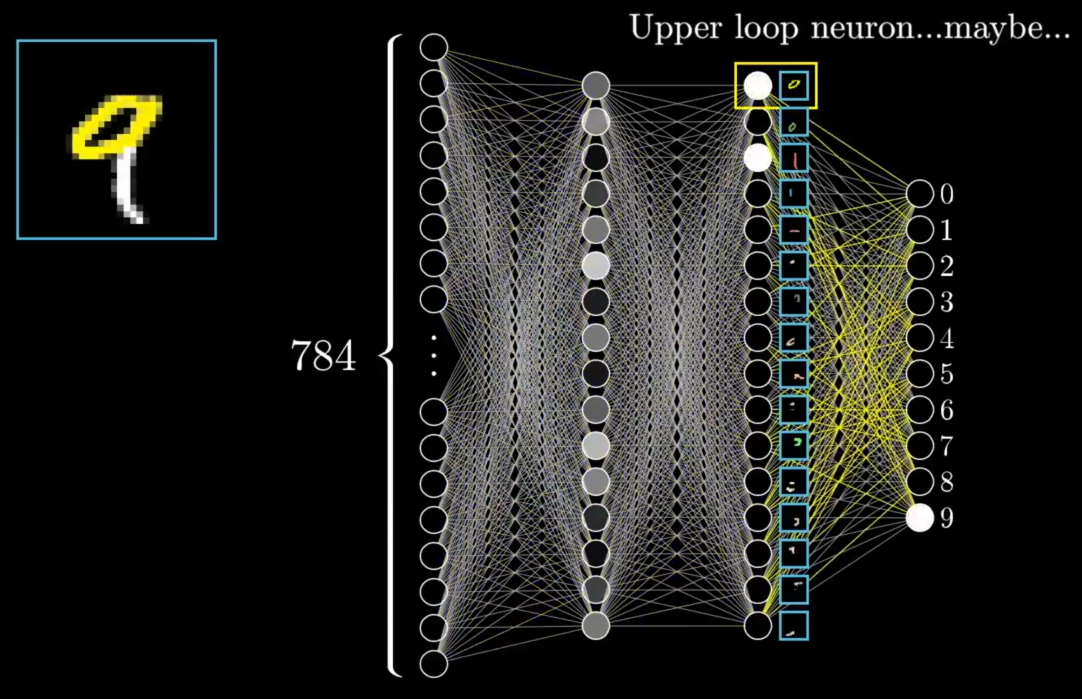
"Of course, that just kicks the problem down the road, because how would you recognize these sub-components, or even learn what the right sub-components should be? And I still haven't even talked about how one layer influences the next. But run with me on this one for a moment.
Recognizing a loop can also break down into sub-problems. One reasonable way to do this would be to first recognize the various little edges that make it up. Similarly, a long line, like the kind you might see in the digits 1 or 4 or 7, well, that's really just a long edge. Or maybe you think of it as a certain pattern of several smaller edges."

"So maybe our hope is that each neuron in the second layer of the network corresponds with the various little edges. Maybe, when an image like this one comes in" — a scrawled 9 flashed up on the screen — "it lights up all of the neurons associated with around 8 to 10 specific little edges, which in turn lights up the neurons associated with the upper loop and a long vertical line, and those light up the neuron associated with a 9."
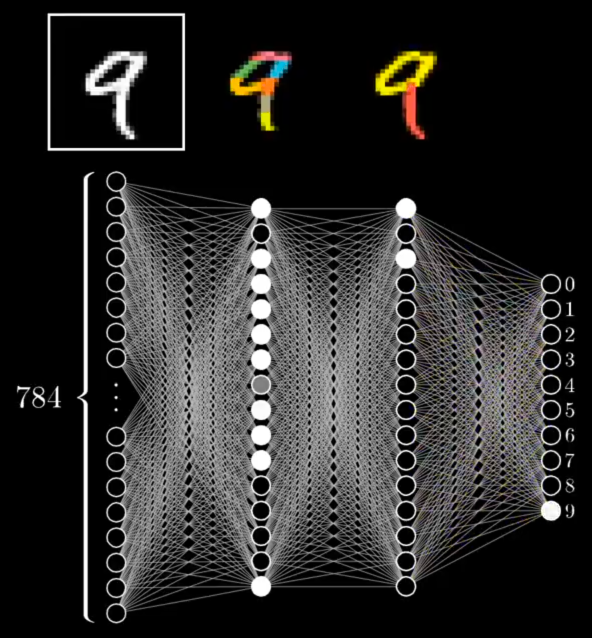
I paused the video and turned to Zac. "Does that make more sense now?" I asked.
"Yeah," Zac replied. "It's fascinating. I guess I always took intelligence for granted. Like, I can point out there on the water and easily identify that as a boat, and touch this wharf here and easily identify it as wood, and look at you and easily identify a derp-"
"Hey!"
"-But I didn't realize what a complex task that is. Essentially, my consciousness is taking in raw data and assigning it meaning. Like, all that data out there combines together to create a boat. But then I also need to know that we use the word 'boat' to describe that object. And what is the word 'boat', anyway? A collection of letters. It's just a bunch of symbols that are quite weird when you think about it. So, I need to look at the raw data of the letters, and then identify each of the individual letters, and then identify the string of letters that combine together into a word, and then assign that word a meaning. And then that word is also spoken a certain way and sounds a certain way, so I need to take in auditory information and then-"
"Yeah," I interrupted. "It's pretty extraordinary. We take our intelligence for granted, but that's the beautiful thing about programming computers: you can't take anything for granted. At the end of the day, you have to build intelligence from scratch using ones and zeros.
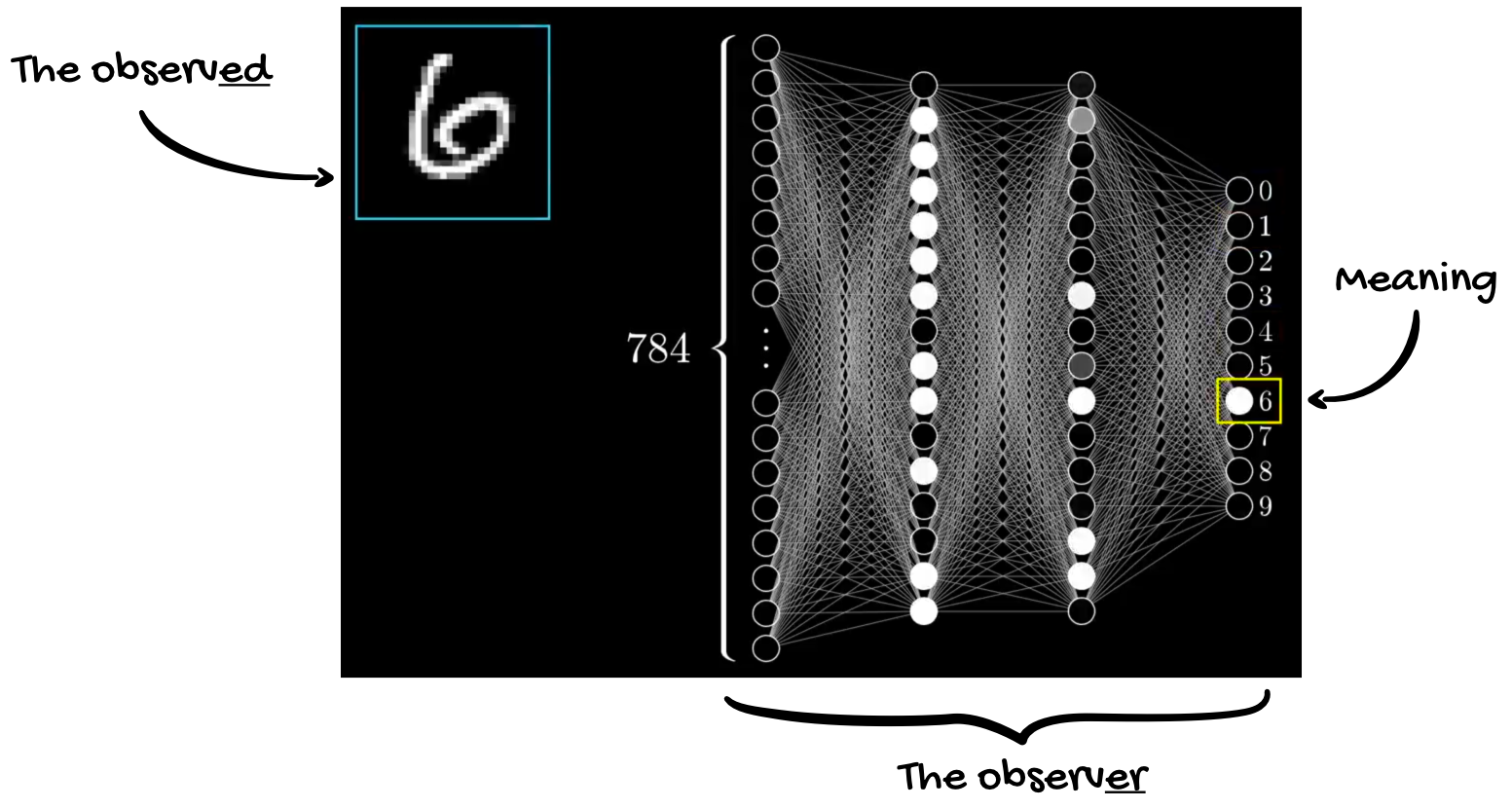
If we examine this closely, at the heart of a neural network we have three components: the observer, the observed, and the meaning that's created when the observer interacts with the observed. The 'observer' is the neural network itself. The 'observed' is the 28 x 28 pixel drawing that is input into the neural network. The 'meaning' is result found in the final layer of the network."
"For example, let's say I observe a plate of spaghetti. The hidden layers in my neural network might process the data so that all I see is a big plate of fattening carbs. I might assign a label like 'bad' or 'naughty' to the spaghetti. Another person might observe the spaghetti, and her hidden layers have been trained completely differently to mine. She takes in the same data and assigns a label like 'delicious' or 'heavenly.' If you give a plate of spaghetti to a starving child in a third world country, the meaning they assign to that data will be completely different from the meaning I assign to it. Is all of this making sense so far?"
"Yep," Zac nodded. "I think I'm keeping up."
